How to Land a Frontier Lab Job
This won’t be a one-size-fits-all suggestion post. Just what I see as a clear path to a desirable position.
It’s been a year since I gave my first lecture on pretraining in my advisor Kai Li’s class.
I came back for another talk this past April and found it enjoyable to revisit my forecasts from last year about prospective research directions to see how they turned out.
I’ll rehash those directly at the end of this post, but wanted to focus most of my discussion on a question I’m being asked increasingly often: how can I build the skills to work at a frontier lab today? I won’t chart every path here, but take the view of giving advice to a younger version of myself.
Who are you to be giving advice on this anyway?
To any new readers here is an overview of my career.
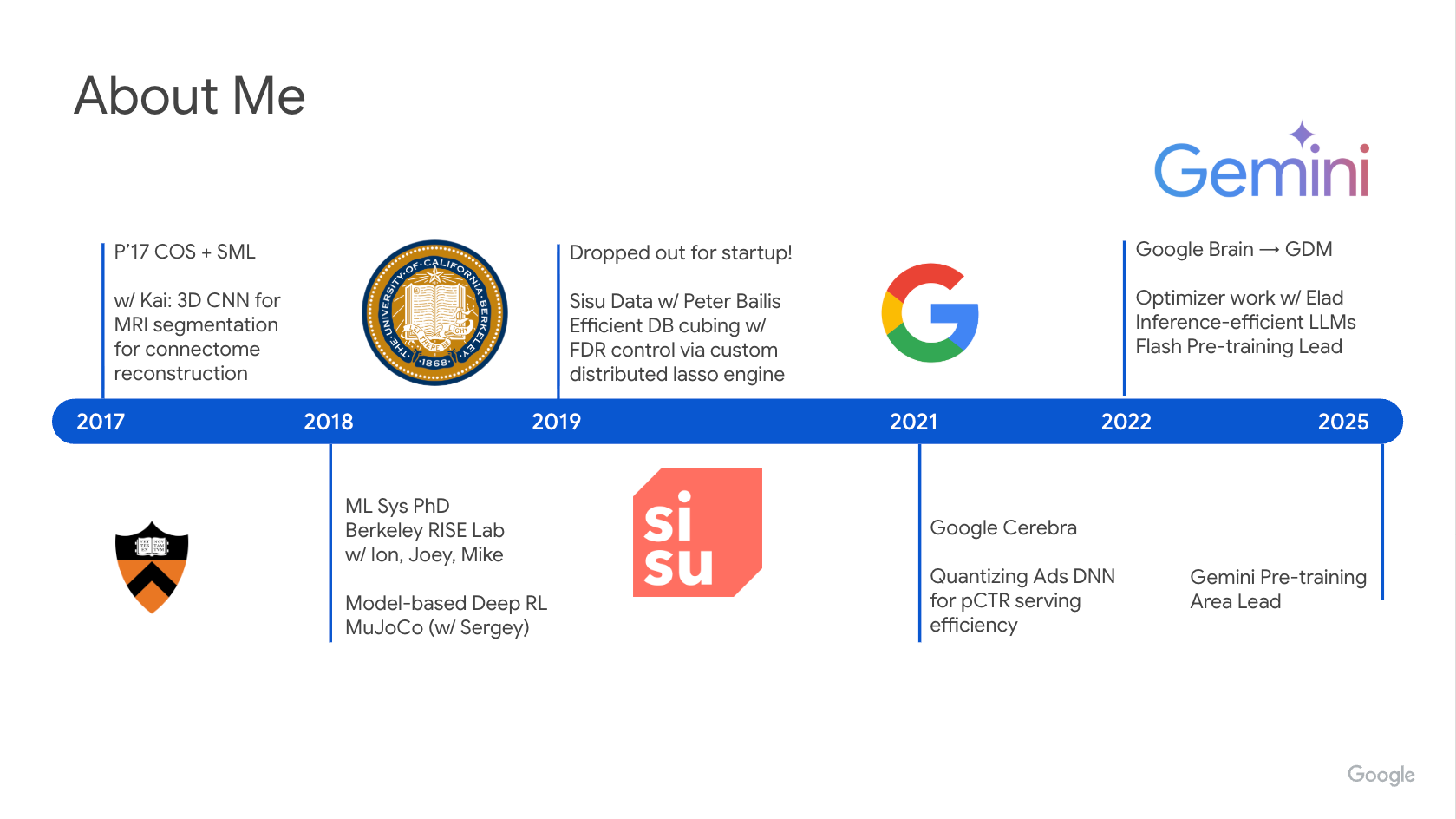
I’ve been incredibly fortunate for all my mentors throughout the process. Being pointed in the right direction is one of the most valuable external factors to success. I wish I could say I plotted this course for myself (or maybe just listened more carefully to the advice I’ve gotten) with long-term planning and intention, but the reality is I just
- consistently locally optimized by reflecting on what I want to accomplish and where I want to be every 6 months and
- never turned up my nose at “menial” work. If you found the right place to dig for gold, just keep digging. Don’t complain about the dirt.
Why is getting into frontier labs difficult?
Finding work in a frontier lab is hard because the competition is so high.
There is always a vanguard of elite college students (both undergrads and PhDs) who do ML research in top-tier conferences, math and programming competitions, and already have connections to these labs through older classmates or friends.
They have context on what problems matter and have been sharpening their already-gifted skillset to optimize for it. Years ago, this cohort would be scooped by Jane Streets and Citadels; more recently it is OpenAI and Anthropic and GDM.
The reason this cohort is so successful is because the underlying traits are highly predictive of success:
- Intent. They picked a high-value problem space to focus on.
- Mathematical maturity. Generalized problem solving is the key tool for ambiguous domains.
- Grit. They have gone through the soul-crushing difficulty and workload that technically rigorous, proof based classes put you under.
What if I’m just starting college?
This brings me to the advice I’d give myself if I was entering college today: do everything you can to join that cohort mentioned above.
Work like a dog.
Take difficult, proof-based classes. Code, obviously. Use AI for what you already know how to do, only, but aggressively so.
Give up your weekends and nights. Burned into my mind is the typical workflow my college friends and I have gone through. We would start from the very morning of Saturday with two big quadruple-shot Panera iced coffees until late, then come back and do it again the following day, hoping to finish early enough to trudge back to our rooms on the other side of campus to get to sleep on time for the start of another week of psets. Rolling deadlines collapse on each other with nothing but another such weekend to look forward to. Outside, clear blue skies host a warm sun shining over the Cottage Club, an eating club we never set foot in, where, locked in our tower atop Lewis Library, the blasting music from its backyard reverberated off the windows as Sunday Funday proceeded differently for those inside versus outside. Not for you. Get that soft sponge in your head, which was mostly a primitive state machine tuned by evolution to hunt and eat and fuck, to think abstractly. Learn to build thought.

Get off your soapbox
OK, fine. Yes, college is still useful, we get it.
What are more concrete steps we can take?
There is no substitute to the above for achieving mathematical maturity, which is essential, but setting this aside, the most obvious way to get hired by a lab is to demonstrate that you have a specific skill that the lab requires.
It seems like a catch-22, how do you get these skills and problems without already being there?
The way out of this is to work at the edges of where frontier labs operate: they spend their time creating LLMs. What do LLMs require to run, and what are the touchpoints for their outputs? This is the direction where frontier labs expand their scope, and thus are the few specific areas that don’t require training LLMs, but are nonetheless essential to the business. They happen to be exactly where you would expect, one below the LLM stack and one above.
- Below the LLM stack sit kernels. Kernels are carefully designed pieces of code which compute part of a neural network program.
- Above the LLM abstraction sit agentic loops. Leveraging the LLM as a grey box, you can harness it to produce useful results.
These two happen to be my two suggestions for research work in last year’s talk. As I mentioned at the outset, I expected academia to progress quite a bit in this area since it doesn’t require frontier resources but still contributes to the frontier. Here’s a few cool works on the matter. I throw in quant research too, quant research is GPU-cheap to do but a great example of how lateral systems thinking can make an impact.
For the most part, reviewing existing research work is a great way to see how people demonstrate contributions in these areas. At the end, I’ll put together a bit of a lesson plan.
Kernel Work
The biggest bottleneck and innermost loop of all LLM work is performance work that makes abstract, logical changes to the LLM practical to run. Every project needs people who can tune the LLMs at the kernel level. It is a skill you can pick up and is the most direct path into the labs.
No, LLMs themselves cannot do this yet. Systems thinking and the math involved is always simple at the face of it: a little bit of algebra will tell you if your bottleneck is communication, or flops, or memory. And your coding agent will always beat you when you set up a question that introduces these concepts. But systems are challenging because they connect to the real world and require lateral thinking and developing new abstractions to resolve. Unless you tell your coding agent to watch out for latch boundedness, it will happily analyze just comms/flops/HBM rooflines, for instance. And whatever the next physical constraint is that didn’t get modeled after that.
How do you get good at kernel work?
You just do it. And it’s just a combination of coding and reasoning about systems. There are plenty of LLMs out there that run slowly on GPUs and TPUs. Just make them run fast. You only need enough accelerators to run a forward pass of the models. You get feedback instantly; it’s the benchmark. Low level coding isn’t the obstacle anymore, it’s awareness and integration of details about physical accelerator devices, as well as a scientific approach to spending time where it matters.
I call this “kernel work” but really it includes a lot more than that:
- Actual device kernel development.
- Inference stack innovations and CPU optimizations.
- Tooling that facilitates R&D around this ecosystem.
Research Progress
It’s helpful to review how researchers have made progress in the area to see what your own contributions should eventually look like.
DSLs
Programming language design has come up as an ancillary area of study to accelerate kernel development. Kernels are difficult pieces of concurrent low-level code. Reasoning about concurrency in this setting requires a deep understanding of the scheduling guarantees the hardware provides. I’ve posted about similar problems in the past.
PL research aims to extract the right abstractions to perform this correctness reasoning into the programming setting directly, without performance compromises. It is an excellent example of “working at the edges” of the LLM that has very high impact, and explains the incentives behind this observation from Yaroslav.
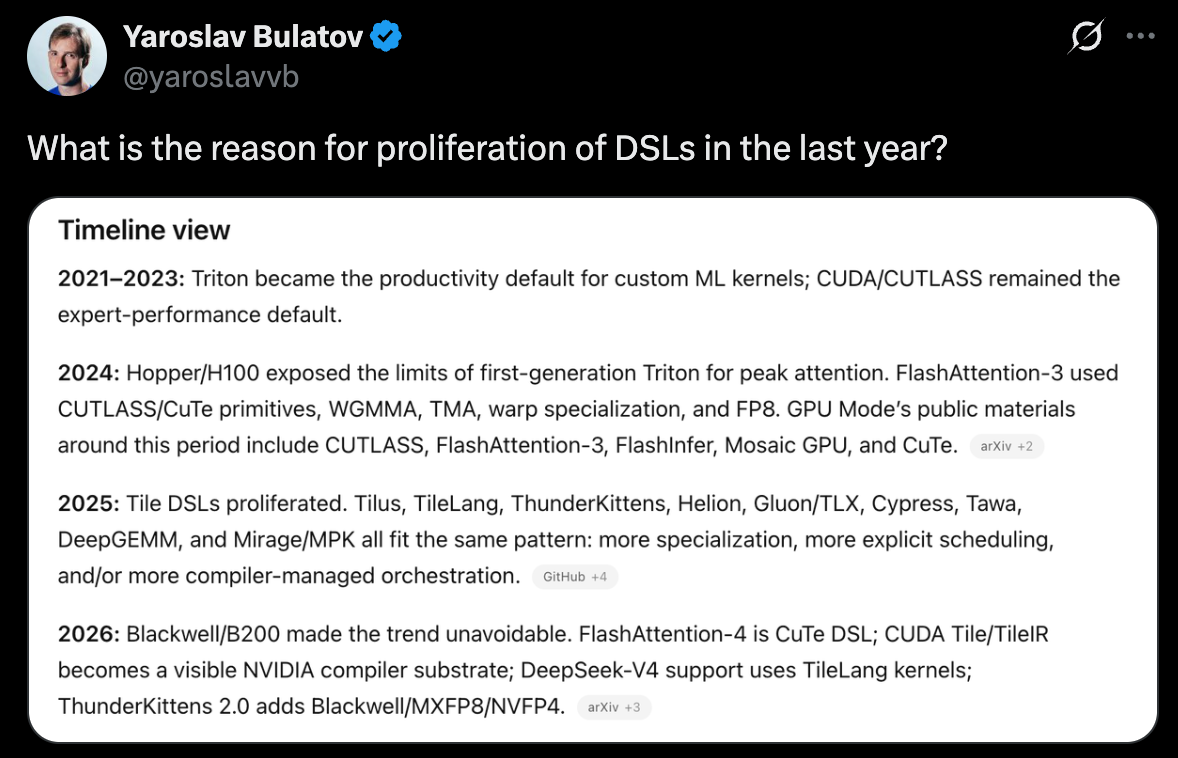
That tweet is also an excellent study list, from which I would specifically call out ThunderKittens.
Flash Attention Series
A perfect segue would be the Flash Attention Series of papers, here I link the recent fourth one targeting B200 GPUs, which itself calls out CuTe DSL. Reading these papers is the best example of the “lateral systems thinking” which you should sharpen to write efficient accelerator code.
In what now seems like a trite pedagogical example, but was worth detailing in a full paper at the time, the “Flash Attention trick” demonstrated how modelling flops alone might steer one to believe that the unfused attention implementation that is a direct transcription of attention math might come about.

If your model of accelerator runtime is only counting flops, you might spend years trying to change the math of the attention operation itself (at potential quality loss, spending lots of GPU-time validating quality experiments about sparse attention whose results can’t be predicted well ahead of time). By considering a new variable, one that’s obvious now in hindsight, such as memory bandwidth, we realize that the operation can be restructured to avoid materializing intermediate values in slow HBM memory.
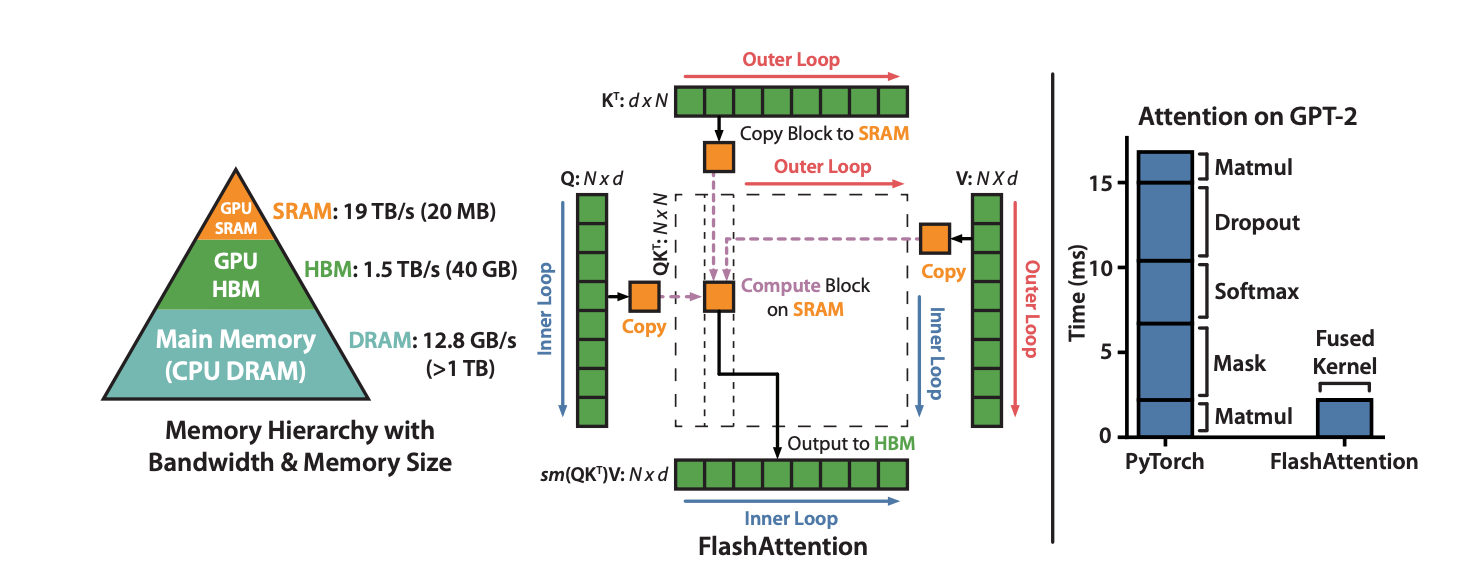
For folks already familiar with the flash attention trick, I urge you not to be dismissive just because you’re already aware of the memory bottleneck: the important part is identifying unmodelled constraints on system performance, which can always be done by zooming out and viewing a system for generating responses and interacting with the user more holistically.
Quantization
Quantization is an excellent field to enter as well, which exists at the edges of the LLM stack. It requires minimal resources and exposes you to the full quality-performance tradeoff.
I recommend starting with LLM.int8(), a classic which exposes you to a strong set of tricks to walk the quality-performance tradeoff. There’s then another good series of papers from Chris De Sa’s group:
A slightly different but still powerful leaf in this tech tree is AQLM.
Further examples
It may seem like all the low hanging fruit has been picked here, but that’s never the case. You can always keep zooming out and assessing the system holistically. Further examples:
- On the decoding side, you might look at approaches like SnapKV to reduce the KV HBM BW bottleneck
- The most meta take, assessing systems research itself, is the Barbarians at the Gate paper.
Agent Work
Before you get too excited, I’m not talking about simply using agents or writing your own CLAUDE.md. I’m talking about setting up rigorous, controlled, technical experiments that assess how single or multiple LLM agents behave.
This is work “at the top of the stack” that nonetheless advances the bleeding edge.
The field here is too new for it to have a clean path like in the kernel case. I’ll admit I’m not an expert here.
There are a couple of clean examples of this, such as the effort that Andrej put in to set up something like autoresearch: investing in facilitating LLMs in creating useful outputs.
At work, I’ve been working with AlphaEvolve and FunSearch as components of my research workflow, where I integrate LLM search in the inner loop for algorithm development. No, I won’t share more here :)
Subject Matter
Of course, it’s not enough to demonstrate that you can contribute above and below the LLM layer of abstraction; you should have a good understanding of the history and general theory surrounding LLMs. By reading and understanding highly cited LM papers through a careful literature review, you internalize the concepts LLM researchers work with and can converse with them more efficiently.
A general history of the very empirical theory of LLMs, outside of the papers mentioned in the slides I just linked above, would include further ML history as well, which now feels ancient but nonetheless arms you with powerful concepts that we still work with every day. Not to mention doing the exercises in these texts helps develop that mathematical maturity I keep talking about.
Great general list of papers on LMs, DL that are worth reading through. A biased lineage from my own history and understanding of the topic is perhaps something I should put together, but out of scope for this article. With enough demand maybe! For now, I’ll just refer you to my pretraining lecture again.
Practical Next Steps
The papers I listed above are nice for reading, exploration of related work, and reconstruction, but what if you need to start with more basic building blocks?
First, get familiar with this style of Reiner analysis (Dwarkesh lecture with Reiner Pope). You should be able to do this stuff in your sleep.
- Go through Jax tutorials
- Read and do every single exercise in the scaling book
An exercise:
Code a ~10M transformer using only jax, flax, optax in free colab using tpu.
Hard code it to accept digits 0-9, space, +, =.
Generate a dataset of simple up-to-3-digit numbers, have it learn addition.
Should train quickly on T4 GPU (pad examples to fixed length)
Derive Chinchilla laws for this; see how they differ for dense vs MoE architectures. Code your solution from scratch in jax by hand if you actually want the learning experience.
Next, assuming you used jax.lax.ragged_dot for the MoE layer; write a pallas kernel that beats ragged dot for F > D by fusing the up/down projections. Find a setting where you notice a measurable forward pass speedup and explain why it’s there.
I’ll put my money where my mouth is: record yourself doing the jax scaling book exercises above with paper and pencil (all of them). Then have a chatbot convert scanned versions of those results to latex. Send it to me (be ready for me to ask for a random subset of videos of you doing the problems!). Similarly screen-record yourself manually writing the code for implementing the transformer from scratch and deriving the Chinchilla laws. It’s a lot of work, but if you do all that, just know I’m hiring in NYC and like to show myself as self-consistent. Send me an email with the scaling law report and the exercise writeup.
I want to emphasize: doing the couple of exercises above is a good start, but it’s not a short circuit that avoids the 5-10 years of signaling the traditional college path would give you. However, it sets you up for the skills and question-asking that might end you up with a public github repo demonstrating something useful and adopted widely by the industry. After that, you get to pick where you want to work.