
The VLAD (vector of locally aggregated descriptors) (no relation!) algorithm was proposed as a mechanism for compacting image descriptors (related follow-on work). This is useful for creating similarity search indices.A reader of my blog referred me to this algorithm, noting that the supposedly vectorized version turns out slower than non-vectorized code. We review indexing and broadcasting rules to diagnose the slowdown and prescribe a fix with a lesser-known numpy gem for what’s known as a ...
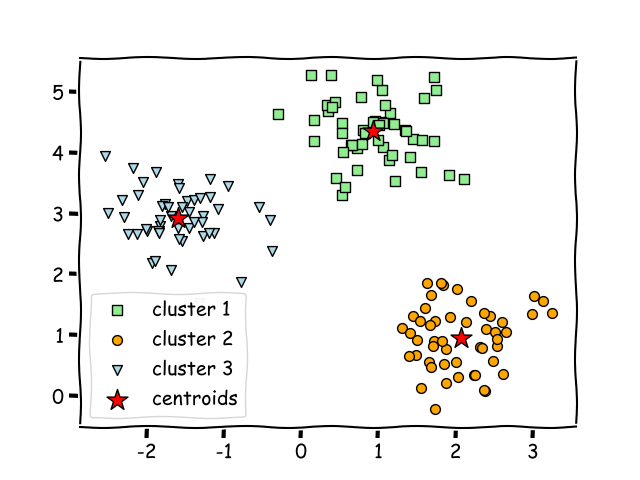
Frequently, we run into situations where we need to deal with arrays of varying sizes in numpy. These result in much slower code that deals with different sizes individually. Luckily, by extracting commutative and associative operations, we can vectorize even in such scenarios, resulting in significant speed improvements. This is especially pronounced when doing the same thing with deep learning packages like torch, because vectorization matters a lot more on a GPU.For instance, take a typica...
In the previous post, we discussed a particular quantity, \(\mathbb{P}\{X=1\} \), where \(X \) follows a Poisson Binomial distribution, parameterized by \(\{p_j\}_{j=1}^n \). This means that \(X=\sum_jX_j \), where \(X_j \) are Bernoulli- \(p_j \) independent random variables.We came up with an \(O(1) \) memory and \(O(n) \) time approach to computing the desired probability, and gave an example where even the best approximations can be poor.What about a more general question? Let’s ta...
This article investigates a fun thought experiment about the Poisson-Binomial distribution.Let’s imagine we’re designing a large hash table. We know up-front we’re going to get \(n \) distinct keys, so let’s number them \(j\in [n] \).Ahead of time, we’re allowed to see the set of hashes the \(j \)-th key will belong to. It is allowed to take on one of \(c_j \) distinct hashes, \(S_j=\{h_1, \cdots, h_{c_j}\}\subset\mathbb{N} \), where at run time the real hash is sampled uniformly (and in...