BERT
In the last two posts, we reviewed Deep Learning and The Transformer. Now we can discuss an interesting advance in NLP, BERT, Bidirectional Encoder Representations from Transformers (arxiv link).
BERT is a self-supervised method, which uses just a large set of unlabeled textual data to learn representations broadly applicable for different language tasks.
At a high level, BERT’s pre-training objective, which is what’s used to get its parameters, is a Language modelling (LM) problem. LM is an instance of parametric modeling applied to language.
Typical LM task: what’s the probability that the next word is “cat” given the sentence is “The dog chased the ????”
Let’s consider a natural language sentence \(x\). In some way, we’d like to construct a loss function \(L\) for a language modeling task. We’ll keep it abstract for now, but, if we set up the model \(M\) right, and have something that generally optimizes \(L(M(\theta), x)\), then we can interpret one of BERT’s theses as the claim that this representation transfers to new domains.
That is, for some very small auxiliary model \(N\) and a set of parameters \(\theta’\) close enough to \(\theta\), we can optimize a different task’s loss (say, \(L’\), the task that tries to classify sentiment \(y\)) by minimizing \(L’(N(\omega)\circ M(\theta’),(x, y))\).
One of the reasons we might imagine this to work is by viewing networks like \(M(\theta’\) as featurizers that create a representation ready for the final layer to do a simple linear classification on.
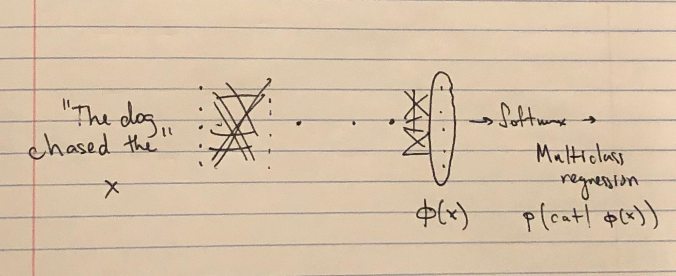
Indeed, the last layer of a neural network performing a classification task is just a logistic regression on the features generated by the layers before it. It makes sense that those features could be useful elsewhere.
Contribution
The motivation for this kind of approach (LM pre-training and then a final fine-tuning step) versus task-specific NLP is twofold:
- Data volume is much larger for the LM pre-training task
- The approach can solve multiple problems at once.
Thus, the contributions of the paper are:
- An extremely robust, generic approach to pretraining. 11 SOTAs in one paper.
- Simple algorithm.
- Effectiveness is profound because (1) the general principle of self-supervision can likely be applied elsewhere and (2) ablation studies in the paper show that representation is the bottleneck.
Technical Insights
The new training procedure and architecture that BERT provides is conceptually simple.
Bert provides deep, bidirectional, context-sensitive encodings.
Why do we need all three of these things? Let’s consider a training task, next sentence prediction (NSP) to demonstrate.
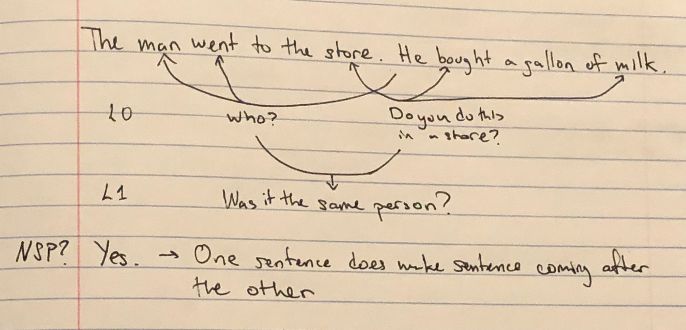
We can’t claim that this is exactly what’s going on in BERT, but clearly as humans we certainly require bidirectional context to answer. In particular, for some kind of logical relation between the entities in a sentence, we first need (bidirectional) context. I.e., to answer if “buying milk” is something we do in a store, we need to look at the verb, object, and location.
What’s more, to answer complicated queries about the coherence of two sentences, we need to layer additional reasoning beyond the logical relations we can infer at the first level. We might be able to detect inconsistencies at L0, but for more complicated interactions we need to look at a relationship between logical relationships (L1 as pictured above).
So, it may make sense that to answer logical queries of a certain nesting depth, we’d need to recursively apply our bidirectional, contextualization representation up to a corresponding depth (namely, stacking Transformers). In the example, we might imagine this query to look like:
was-it-the-same-person(
who-did-this("man", "went"),
who-did-this("he", "bought")) &&
is-appropriate-for-location(
"store", "bought", "milk")
Related work
It’s important to describe existing related work that made strides in this direction. Various previous deep learning architectures have independently proposed using LM for transfer learning to other tasks and deep, bidirectional context (but not all at once).
In particular, relevant works are GloVe, ELMo, and GPT.

Training
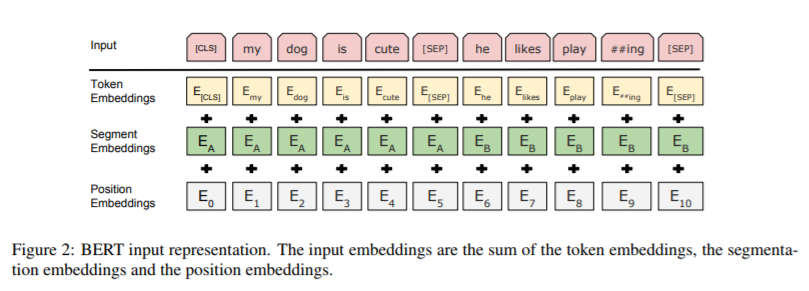
As input, BERT uses the BooksCorpus (800M words) and English Wikipedia (2,500M words), totaling 3.3B words, split into a vocabulary of 33K word pieces. There were a few standard NLP featurization techniques applied to this as well (lower casing, for instance), though I think the architecture could’ve handled richer English input.
But what’s the output? Given just the inputs, how can we create a loss that learns a good context-sensitive representation of each word? This needs to be richer than the context-free representation of each word (i.e., the embedding that each word piece starts as in the first layer of the input to the BERT network).
We might try to recover the original input embedding, but then the network would just learn the identity function. This is the correct answer if we’re just learning on the joint distribution of \((x, x)\) between a sentence and itself.
Instead, BERT trains on sequence recovery. That is, our input is a sentence \(x_{-i}\) missing its \(i\)-th word, and our output is the \(i\)-th word itself, \(x_i\). This is implemented efficiently with masking in practice. That is, the input-output pair is \((\text{“We went [MASK] at the mall.”}, \text{“shopping”})\). In the paper, [MASK] is the placeholder for a missing word.
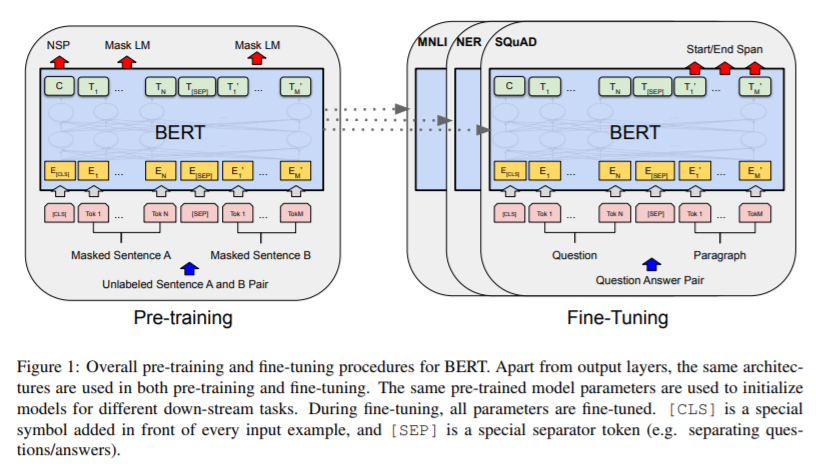
In addition, BERT adds an auxiliary task, NSP, where a special [CLS] classification token is used at the beginning of a sentence that serves as a marker for “this token should represent the whole context of the input sentence(s),” which is then used as a single fixed-width input for classification. This improves performance slightly (see Table 15 in the original work).
That’s essentially it.
BERT = Transformer Encoder + MLM + NSP
There’s an important caveat due to training/test distribution mismatch. See the last section, Open Questions, below.
Fine-tuning
For fine tuning, we just add one more layer on top of the final encoded sequence that BERT generates.
In the case of class prediction, we apply a classifier to the fixed width embedding of the [CLS] marker.
In the case of subsequence identification, like in SQuAD, we want to select a start and end by using a start classifier and end classifier applied to each token in the final output sequence.
For instance, a network is handed a paragraph like the following:
One of the most famous people born in Warsaw was Maria Skłodowska-Curie, who achieved international recognition for her research on radioactivity and was the first female recipient of the Nobel Prize. Famous musicians include Władysław Szpilman and Frédéric Chopin. Though Chopin was born in the village of Żelazowa Wola, about 60 km (37 mi) from Warsaw, he moved to the city with his family when he was seven months old. Casimir Pulaski, a Polish general and hero of the American Revolutionary War, was born here in 1745.
And then asked a reading comprehension question like “How old was Chopin when he moved to Warsaw with his family?” to which the answer is the subsequence “seven months old.” Hard stuff! And BERT performs at or above human level.
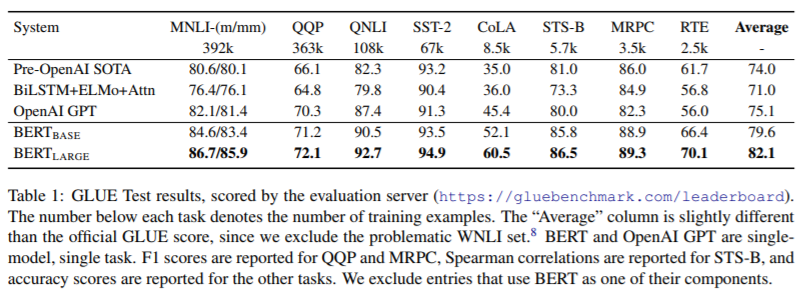
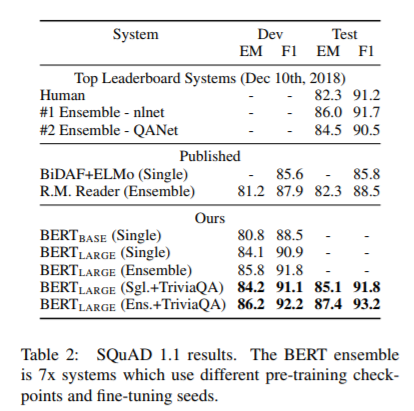
Conclusions
The BERT model is extremely simple, to the point where there’s a mismatch with intuition.
There seem to be some seemingly spurious decisions that don’t have a big effect on training.
First, the segment embeddings indicate different sentences in inputs, but positional embeddings provide positional information anyway. This is seemingly redundant information the network needs to learn to combine.
Second, the start and end indicators for the span predicted for SQuAD are computed independently, where it might make sense to compute the end conditional on the start position. Indeed, it’s possibly to get an end before the start (in which case the span is considered empty).
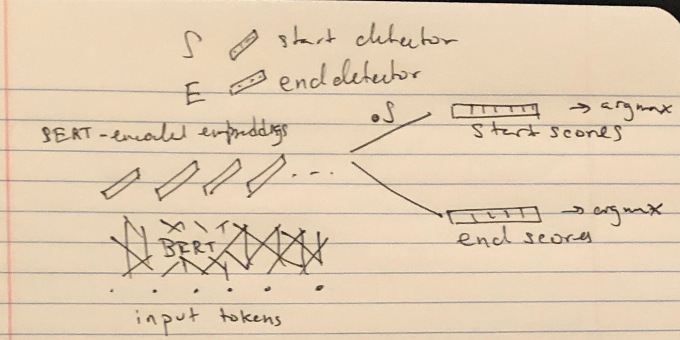
There are probably many such smaller modeling improvements we could make. But the point is that it’s a waste of time. If anything is the most powerful table to take away from this paper, it’s Table 6.
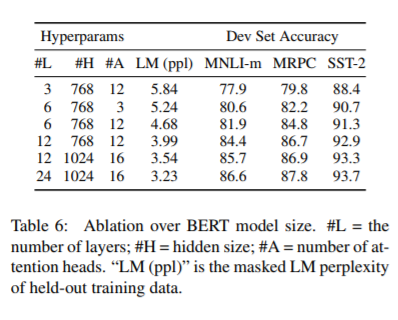
Above any kind of task-specific tuning or model improvements, the longest pole in the tent is representation. Investing effort in finding the “right” representation (here, bidirectional, deep, contextual word piece embeddings) is what maximizes broad applicability and the potential for transfer learning.

Open Questions
Transfer Learning Distribution Mismatch
At the end of Section 3.1, we notice something weird. In the masked language modeling task, our job is to derive what the [MASK] token was.
But in the evaluation tasks, [MASK] never appears. To combat this “mismatch” between the distribution of evaluation task tokens and that of the MLM task, occasionally full sequences are shown without the [MASK] tokens, in which the network is expected to recover the identity functions.
Appendix C.2 digs into the robustness of BERT with respect to messing around with the distribution. This is definitely something that deserves some attention.
During pre-training, we’re minimizing a loss with respect to a distribution that doesn’t match the test distribution (where we randomly remove the mask). How is this a well-posed learning problem?
How much should we smooth the distribution with the mask removals? It’s unclear how to properly set up the “mismatch amount”.
Richer Inputs
Based on the ability of BERT to perform well even with redundant encodings (segment encoding and positional encoding), and given its large representational capacity, why operate BERT on word pieces? Why not include punctuation or even HTML markup from Wikipedia?
This kind of input could surely offer more signal for fine tuning.