Articles by category: deep-learning
graph-processing parallel distributed-systems online-learning machine-learning my-whitepapers hardware-acceleration interview-question tools optimization numpy-gems joke-post philosophy causal statistics numpy tricks history llm pretraining career
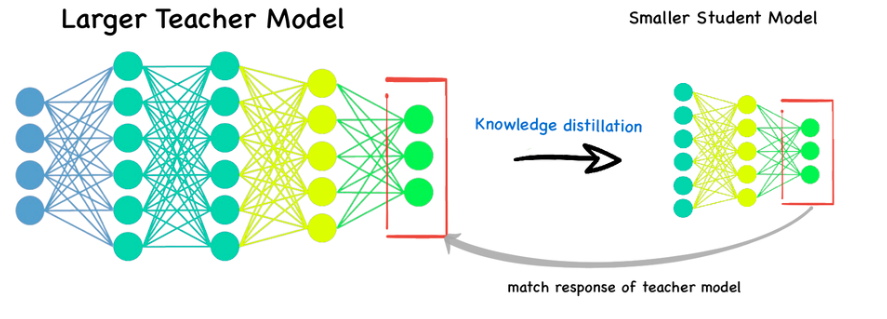
Distillation WalkthroughDistillation is a critical technique towards improving a network’s quality while keeping its serving latency constant.This is becoming crucial as people focus on serving larger and larger models. Image found on LinkedIn.Distillation is a powerful technique, but a couple things about it are quite mystical. The purpose of this post is to: Provide a very high level explainer (but mostly refer to source papers) of distillation. Show that you can create a simple, linear e...
BERTIn the last two posts, we reviewed Deep Learning and The Transformer. Now we can discuss an interesting advance in NLP, BERT, Bidirectional Encoder Representations from Transformers (arxiv link).BERT is a self-supervised method, which uses just a large set of unlabeled textual data to learn representations broadly applicable for different language tasks.At a high level, BERT’s pre-training objective, which is what’s used to get its parameters, is a Language modelling (LM) problem. LM is a...
BERT Prerequisite 2: The TransformerIn the last post, we took a look at deep learning from a very high level (Part 1). Here, we’ll cover the second and final prerequisite for setting the stage for discussion about BERT, the Transformer.The Transformer is a novel sequence-to-sequence architecture proposed in Google’s Attention is All You Need paper. BERT builds on this significantly, so we’ll discuss here why this architecture was important.The ChallengeRecall the language of the previous post...
A Modeling Introduction to Deep LearningIn this post, I’d like to introduce you to some basic concepts of deep learning (DL) from a modeling perspective. I’ve tended to stay away from “intro” style blog posts because: There are so, so many of them. They’re hard to keep in focus.That said, I was presenting on BERT for a discussion group at work. This was our first DL paper, so I needed to warm-start a technical audience with a no-frills intro to modeling with deep nets. So here we are, tryin...
Deep Learning Learning PlanThis is my plan to on-board myself with recent deep learning practice (as of the publishing date of this post). Comments and recommendations via GitHub issues are welcome and appreciated! This plan presumes some probability, linear algebra, and machine learning theory already, but if you’re following along Part 1 of the Deep Learning book gives an overview of prerequisite topics to cover.My notes on these sources are publicly available, as are my experiments. Intro...
Non-convex First Order MethodsThis is a high-level overview of the methods for first order local improvement optimization methods for non-convex, Lipschitz, (sub)differentiable, and regularized functions with efficient derivatives, with a particular focus on neural networks (NNs).\[\argmin_\vx f(\vx) = \argmin_\vx \frac{1}{n}\sum_{i=1}^nf_i(\vx)+\Omega(\vx)\]Make sure to read the general overview post first. I’d also reiterate as Moritz Hardt has that one should be wary of only looking at con...
Neural Network Optimization MethodsThe goal of this post and its related sub-posts is to explore at a high level how the theoretical guarantees of the various optimization methods interact with non-convex problems in practice, where we don’t really know Lipschitz constants, the validity of the assumptions that these methods make, or appropriate hyperparameters. Obviously, a detailed treatment would require delving into intricacies of cutting-edge research. That’s not the point of this post, w...