Articles by category: optimization
graph-processing parallel distributed-systems online-learning machine-learning my-whitepapers hardware-acceleration interview-question tools deep-learning numpy-gems joke-post philosophy causal statistics numpy tricks history llm pretraining career
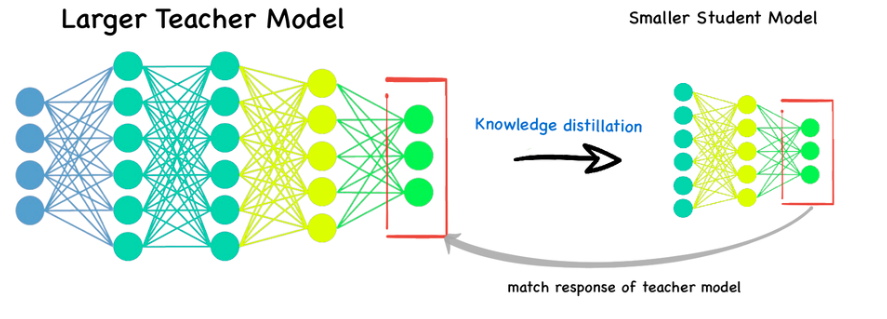
Distillation WalkthroughDistillation is a critical technique towards improving a network’s quality while keeping its serving latency constant.This is becoming crucial as people focus on serving larger and larger models. Image found on LinkedIn.Distillation is a powerful technique, but a couple things about it are quite mystical. The purpose of this post is to: Provide a very high level explainer (but mostly refer to source papers) of distillation. Show that you can create a simple, linear e...
IntroductionIn this blog post, I’ll provide data stream background, applied context, motivation, and an overview for my recent work, Sketchy, co-authored with Xinyi Chen, Y. Jennifer Sun, Rohan Anil, and Elad Hazan, which will be featured in NeurIPS 2023 proceedings.I really enjoyed working on this project because it simultaneously scratches different methodological itches of mine, from data stream sketching to online convex optimization. However, the algorithm introduced here was borne out o...

A serpentine wall, or crinkle crankle wall, may seem like a surprising structure to use for fences, but may end up being more efficient in terms of building material than a straight fence which must withstand the same horizontal forces.In a post which is the raison d’etre for this one, John D. Cook derives a formula for computing the arc length of a sinusoidal curve. By assuming that such a sinusoidally-shaped wall could withstand lateral forces as much as a straight wall would, had the strai...
Non-convex First Order MethodsThis is a high-level overview of the methods for first order local improvement optimization methods for non-convex, Lipschitz, (sub)differentiable, and regularized functions with efficient derivatives, with a particular focus on neural networks (NNs).\[\argmin_\vx f(\vx) = \argmin_\vx \frac{1}{n}\sum_{i=1}^nf_i(\vx)+\Omega(\vx)\]Make sure to read the general overview post first. I’d also reiterate as Moritz Hardt has that one should be wary of only looking at con...
Neural Network Optimization MethodsThe goal of this post and its related sub-posts is to explore at a high level how the theoretical guarantees of the various optimization methods interact with non-convex problems in practice, where we don’t really know Lipschitz constants, the validity of the assumptions that these methods make, or appropriate hyperparameters. Obviously, a detailed treatment would require delving into intricacies of cutting-edge research. That’s not the point of this post, w...