Articles by category: causal
graph-processing parallel distributed-systems online-learning machine-learning my-whitepapers hardware-acceleration interview-question tools optimization deep-learning numpy-gems joke-post philosophy statistics numpy tricks history llm pretraining career
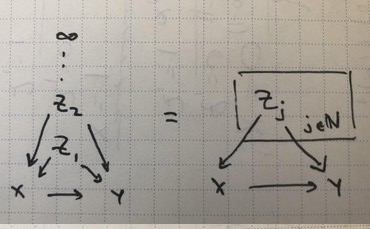
One neat takeaway from the previous post was really around the structure of what we were doing.What did it take for the infinite DAG we were building to become a valid probability distribution?We can throw some things out there that were necessary for its construction. The infinite graph needed to be a DAG We needed inductive “construction rules” $\alpha,\beta$ where we could derive conditional kernels from a finite subset of infinite parents to a larger subset of the infinite parents. The...
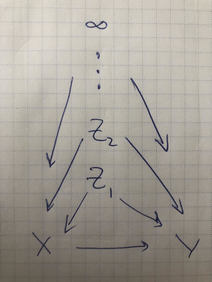
This is Problem 9.11 in Elements of Causal Inference._Construct a single Bayesian network on binary $X,Y$ and variables $\{Z_j\}_{j=1}^\infty$ where the difference in conditional expectation,\[\begin{align}\Delta_j(\vz_{\le j}) &=\\& \CE{Y}{X=1, Z_{\le j}=\vz_{\le j}}-\\& \CE{Y}{X=0, Z_{\le j}=\vz_{\le j}}\,\,,\end{align}\]satisfies $\DeclareMathOperator\sgn{sgn}\sgn \Delta_j=(-1)^{j}$ and $\abs{\Delta_j}\ge \epsilon_j$ for some fixed $\epsilon_j>0$. $\Delta_0$ is unconstrained...
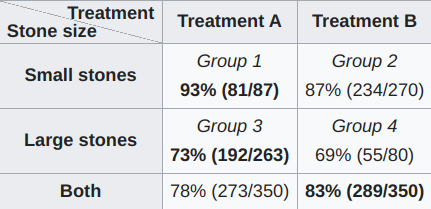
In most data analysis, especially in business contexts, we’re looking for answers about how we can do better. This implies that we’re looking for a change in our actions that will improve some measure of performance.There’s an abundance of passively collected data from analytics. Why not point fancy algorithms at that?In this post, I’ll introduce a counterexample showing why we shouldn’t be able to extract such information easily.Simpson’s ParadoxThis has been explained many times, so I’ll be...